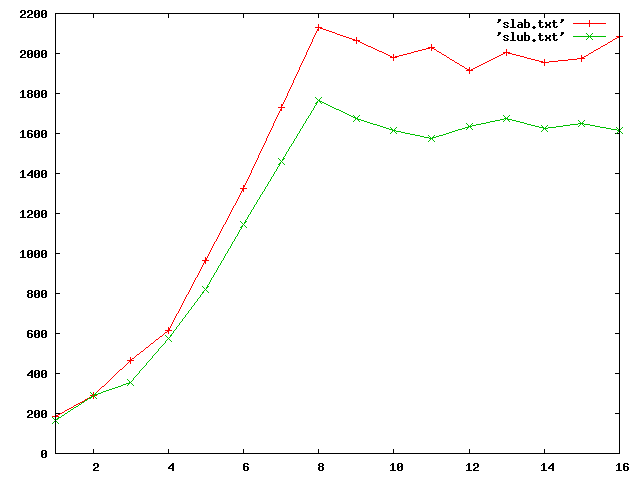
Hi, Just ran some tbench numbers (from dbench-3.04), on a 2 socket, 8 core x86 system, with 1 NUMA node per socket. With kernel 2.6.24-rc2, comparing slab vs slub allocators. I run from 1 to 16 client threads, 5 times each, and restarting the tbench server between every run. I'm just taking the highest of each of the 5 tests (because the scheduler placement can sometimes be poor). It's not completely scientific, but from the graph you can guess it is relatively stable and seems significant. Summary: slub is consistently slower. When all CPUs are saturated, it is around 20% slower. Attached is a graph (x is nrclients, y is throughput MB/s) If I can help with reproducing it or testing anything, let me know. I'll be trying out a few other benchmarks too... anything you want me to test specifically and I can try. Thanks, Nick
Attachment:
slab.png
Description: PNG image
{kind=link}
- Follow-Ups:
- Re: 2.6.24-rc2 slab vs slob tbench numbers
- From: Matt Mackall <[email protected]>
- Re: 2.6.24-rc2 slab vs slob tbench numbers
- From: Christoph Lameter <[email protected]>
- Re: 2.6.24-rc2 slab vs slob tbench numbers
- Prev by Date: Re: [PATCH] Don't fail ata device revalidation for bad _GTF methods
- Next by Date: Re: iozone write 50% regression in kernel 2.6.24-rc1
- Previous by thread: [PATCH 1/1]: oProfile: oops when profile_pc() return ~0LU
- Next by thread: Re: 2.6.24-rc2 slab vs slob tbench numbers
- Index(es):
 |