* Nicholas Miell <[email protected]> wrote:
> Does CFS still generate the following sysbench graphs with 2.6.23, or
> did that get fixed?
>
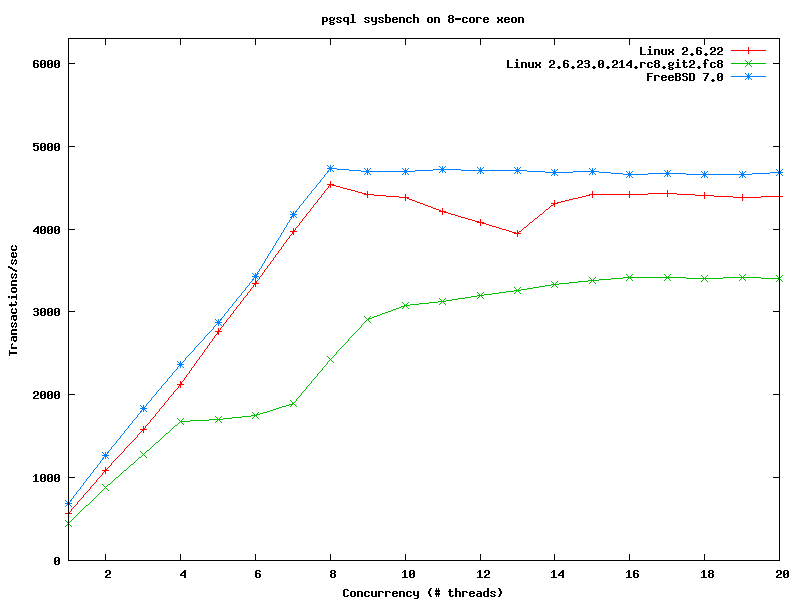
> http://people.freebsd.org/~kris/scaling/linux-pgsql.png
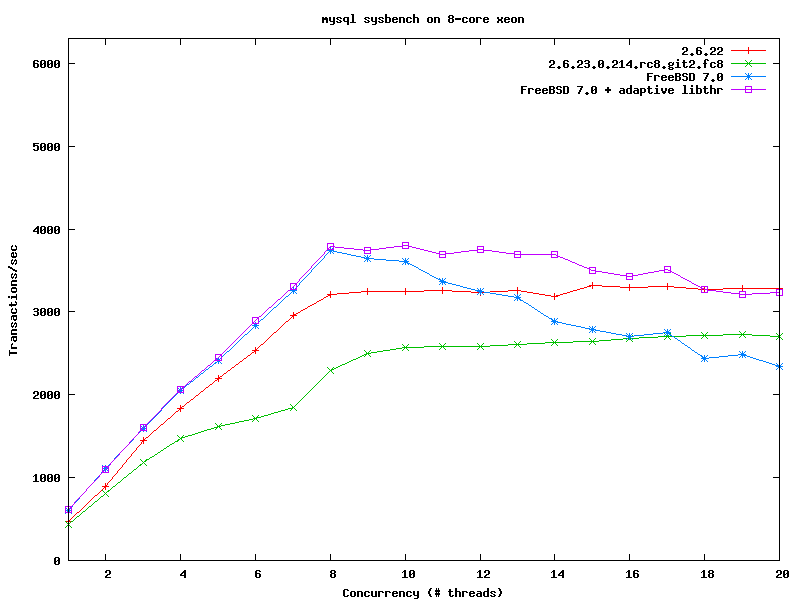
> http://people.freebsd.org/~kris/scaling/linux-mysql.png
as far as my testsystem goes, v2.6.23 beats v2.6.22.9 in sysbench:
http://redhat.com/~mingo/misc/sysbench.jpg
As you can see it in the graph, v2.6.23 schedules much more consistently
too. [ v2.6.22 has a small (but potentially statistically insignificant)
edge at 4-6 clients, and CFS has a slightly better peak (which is
statistically insignificant). ]
( Config is at http://redhat.com/~mingo/misc/config, system is Core2Duo
1.83 GHz, mysql-5.0.45, glibc-2.6. Nothing fancy either in the config
nor in the setup - everything is pretty close to the defaults. )
i'm aware of a 2.6.21 vs. 2.6.23 sysbench regression report, and it
apparently got resolved after various changes to the test environment:
http://jeffr-tech.livejournal.com/10103.html
" [<CFS>] has virtually no dropoff and performs better under load than
the default 2.6.21 scheduler. " (paraphrased)
(The new link you posted, just a few hours after the release of v2.6.23,
has not been reported to lkml before AFAICS - when did you become aware
of it? If you learned about it before v2.6.23 it might have been useful
to report it to the v2.6.23 regression list.)
At a quick glance there are no .configs or other testing details at or
around that URL that i could use to reproduce their result precisely, so
at least a minimal bugreport would be nice.
In any case, here are a few general comments about sysbench numbers:
Sysbench is a pretty 'batched' workload: it benefits most from batchy
scheduling: the client doing as much work as it can, then server doing
as much work as it can - and so on. The longer the client can work the
more cache-efficient the workload is. Any round-trip to the server due
to pesky preemption only blows up the cache footprint of the workload
and gives lower throughput.
This kind of workload would probably run best on DOS or Windows 3.11,
with no preemptive scheduling done at all. In other words: run both
mysqld and the client as SCHED_FIFO to get the best performance out of
it. So in that sense the workload is a bit similar to dbench.
The other thing is that mysqld does _tons_ of sys_time() calls, so GTOD
differences between .22 and .23 might cause extra overhead - especially
with 8 CPUs/cores. Does the sys_time() scalability patch below improve
sysbench performance for you? (i'm not sure about psqld)
If it's indeed due to batched vs. well-spread-out scheduling behavior
(which is possible), there are a few things you could do to make
scheduling more batched:
1) start the DB daemon up as SCHED_BATCH:
schedtool -B -e service mysqld restart
(and do the same with the client-side commands as well)
or:
schedtool -B $$
to mark the parent shell as SCHED_BATCH - then start up the DB and
start the client workload. (All other tasks not started from this
shell will still be SCHED_OTHER, so only your mysql workload will be
affected.) For example "beagled" already runs under SCHED_BATCH by
default.
SCHED_BATCH will cause the scheduler to batch up the workload more.
You basically tell the scheduler: "this workload really wants
throughput above all", and the scheduler takes that hint and acts
upon it. (it's still not as drastic as SCHED_FIFO, it's somewhere
between SCHED_OTHER and SCHED_FIFO, in terms of batching. Start up
your DB and your client as SCHED_FIFO via "schedtool -F -p 10 ..." to
establish the best-case batching win.)
2) check out the v22 CFS backport patch which has the latest & greatest
scheduler code, from http://people.redhat.com/mingo/cfs-scheduler/ .
Does performance go up for you with it? It's somewhat less
preemption-eager, which might as well make the crutial difference for
sysbench.
3) if it's enabled, disable CONFIG_PREEMPT=y. CONFIG_PREEMPT can cause
unwanted overscheduling and cache-trashing under overload.
hope this helps, and i'm definitely interested in more feedback about
this,
Ingo
Index: linux/kernel/time.c
===================================================================
--- linux.orig/kernel/time.c
+++ linux/kernel/time.c
@@ -57,11 +57,7 @@ EXPORT_SYMBOL(sys_tz);
*/
asmlinkage long sys_time(time_t __user * tloc)
{
- time_t i;
- struct timespec tv;
-
- getnstimeofday(&tv);
- i = tv.tv_sec;
+ time_t i = get_seconds();
if (tloc) {
if (put_user(i,tloc))
Index: linux/kernel/time/timekeeping.c
===================================================================
--- linux.orig/kernel/time/timekeeping.c
+++ linux/kernel/time/timekeeping.c
@@ -49,19 +49,12 @@ struct timespec wall_to_monotonic __attr
static unsigned long total_sleep_time; /* seconds */
EXPORT_SYMBOL(xtime);
-
-#ifdef CONFIG_NO_HZ
static struct timespec xtime_cache __attribute__ ((aligned (16)));
static inline void update_xtime_cache(u64 nsec)
{
xtime_cache = xtime;
timespec_add_ns(&xtime_cache, nsec);
}
-#else
-#define xtime_cache xtime
-/* We do *not* want to evaluate the argument for this case */
-#define update_xtime_cache(n) do { } while (0)
-#endif
static struct clocksource *clock; /* pointer to current clocksource */
-
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to [email protected]
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
[Index of Archives]
[Kernel Newbies]
[Netfilter]
[Bugtraq]
[Photo]
[Stuff]
[Gimp]
[Yosemite News]
[MIPS Linux]
[ARM Linux]
[Linux Security]
[Linux RAID]
[Video 4 Linux]
[Linux for the blind]
[Linux Resources]
{kind=link}
{kind=link}
{kind=link}
