On Wednesday 14 November 2007 17:37, David Miller wrote: > From: Nick Piggin <[email protected]> > > I'm doing some oprofile runs now to see if I can get any more info. OK, in vanilla kernels, the page allocator definitely shows higher in the results (than with Herbert's patch reverted). 27516 2.7217 get_page_from_freelist 21677 2.1442 __rmqueue_smallest 20513 2.0290 __free_pages_ok 18725 1.8522 get_pageblock_flags_group Just these account for nearly 10% of cycles. __alloc_skb shows up higher too. free_hot_cold_page() shows a lot lower though, which might indicate that actually there is more higher order allocation activity (I'll check that next). **** SLUB, avg throughput 1548 CPU: AMD64 family10, speed 1900 MHz (estimated) Counted CPU_CLK_UNHALTED events (Cycles outside of halt state) with a unit mask of 0x00 (No unit mask) count 100000 samples % symbol name 94636 9.3609 copy_user_generic_string 38932 3.8509 ipt_do_table 34746 3.4369 tcp_v4_rcv 29539 2.9218 skb_release_data 27516 2.7217 get_page_from_freelist 26046 2.5763 tcp_sendmsg 24482 2.4216 local_bh_enable 22910 2.2661 ip_queue_xmit 22113 2.1873 ktime_get 21677 2.1442 __rmqueue_smallest 20513 2.0290 __free_pages_ok 18725 1.8522 get_pageblock_flags_group 18580 1.8378 tcp_recvmsg 18108 1.7911 __napi_schedule 17593 1.7402 schedule 16998 1.6813 tcp_ack 16102 1.5927 dev_hard_start_xmit 15751 1.5580 system_call 15707 1.5536 net_rx_action 15150 1.4986 __switch_to 14988 1.4825 tcp_transmit_skb 13921 1.3770 kmem_cache_free 13398 1.3253 __mod_timer 13243 1.3099 tcp_rcv_established 13109 1.2967 __tcp_select_window 11022 1.0902 __tcp_push_pending_frames 10732 1.0615 set_normalized_timespec 10561 1.0446 netif_rx 8840 0.8744 netif_receive_skb 7816 0.7731 nf_iterate 7300 0.7221 __update_rq_clock 6683 0.6610 _read_lock_bh 6504 0.6433 sys_recvfrom 6283 0.6215 nf_hook_slow 6188 0.6121 release_sock 6172 0.6105 loopback_xmit 5927 0.5863 __alloc_skb 5707 0.5645 tcp_cleanup_rbuf 5538 0.5478 tcp_event_data_recv 5517 0.5457 tcp_v4_do_rcv 5516 0.5456 process_backlog **** SLUB, net patch reverted. Avg throughput 1933MB/s Counted CPU_CLK_UNHALTED , count 100000 samples % symbol name 95895 9.5094 copy_user_generic_string 50259 4.9839 ipt_do_table 39408 3.9079 skb_release_data 37296 3.6984 tcp_v4_rcv 31309 3.1047 ip_queue_xmit 31308 3.1046 local_bh_enable 24052 2.3851 net_rx_action 23786 2.3587 __napi_schedule 21426 2.1247 tcp_recvmsg 21075 2.0899 schedule 20938 2.0763 dev_hard_start_xmit 20222 2.0053 tcp_sendmsg 19775 1.9610 tcp_ack 19717 1.9552 system_call 19495 1.9332 set_normalized_timespec 18584 1.8429 __switch_to 17022 1.6880 tcp_rcv_established 14655 1.4533 tcp_transmit_skb 14466 1.4345 __mod_timer 13820 1.3705 loopback_xmit 13776 1.3661 get_page_from_freelist 13288 1.3177 netif_receive_skb 9718 0.9637 _read_lock_bh 9625 0.9545 nf_iterate 9440 0.9361 netif_rx 9148 0.9072 free_hot_cold_page 8633 0.8561 __update_rq_clock 7668 0.7604 sys_recvfrom 7578 0.7515 __tcp_push_pending_frames 7311 0.7250 find_pid_ns 7178 0.7118 nf_hook_slow 6655 0.6599 sysret_check 6313 0.6260 release_sock 6290 0.6237 tcp_cleanup_rbuf 6263 0.6211 __tcp_select_window 6235 0.6183 process_backlog 5920 0.5871 ip_local_deliver_finish 5651 0.5604 ip_rcv 5239 0.5195 ip_finish_output 5058 0.5016 kmem_cache_free 5016 0.4974 thread_return > Here are some other things you can play around with: > > 1) Monitor the values of skb->len and skb->data_len for packets > going over loopback. OK, I've taken a log2 histogram of ->len and ->data_len sizes. I'll attach the plots (xaxis is byte value of most significant bit set, y axis is number of occurances, logscale on X so 0 isn't there :( ). If you want to see the patch or raw data, let me know. len looks very similar for both kernels, although the reverted kernel has significantly higher frequency at most points. tbench unfortunately is only possible to do it time-based, so this is rougly expected. data_len has a spike that shifts up to 512-1023, from 256-511, when reverting Herbert's patch. Again, I believe the magnitudes of the spikes should actually be pretty close if we were doing an equal amount of work. I can't see that these numbers show much useful, unfortunately. > 2) Try removing NETIF_F_SG in drivers/net/loopback.c's dev->feastures > setting. Will try that now.
Attachment:
data.png
Description: PNG image
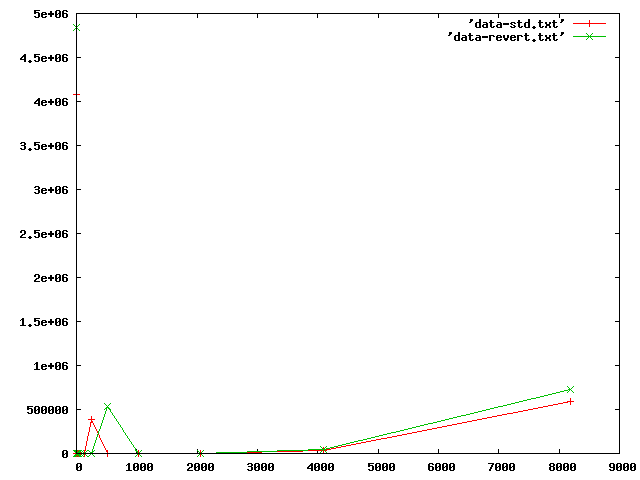{kind=link}
Attachment:
len.png
Description: PNG image
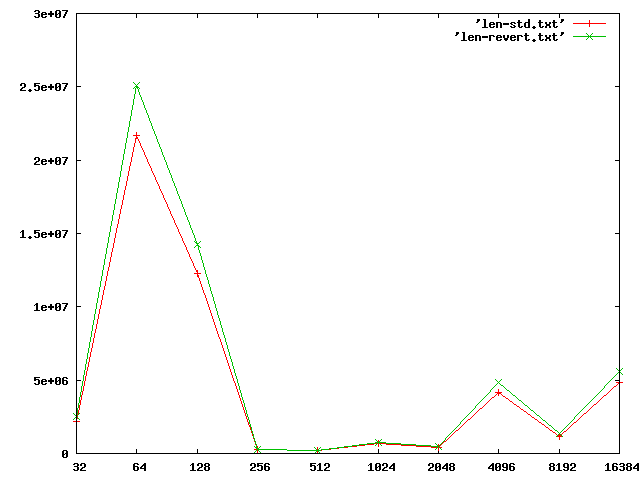{kind=link}
- Follow-Ups:
- References:
- Re: 2.6.24-rc2: Network commit causes SLUB performance regression with tbench
- From: Nick Piggin <[email protected]>
- Re: 2.6.24-rc2: Network commit causes SLUB performance regression with tbench
- From: Nick Piggin <[email protected]>
- Re: 2.6.24-rc2: Network commit causes SLUB performance regression with tbench
- From: David Miller <[email protected]>
- Re: 2.6.24-rc2: Network commit causes SLUB performance regression with tbench
- Prev by Date: Re: 2.6.24-rc2-mm1 -- mkfs failing on variety of fs types
- Next by Date: [PATCH] Fix the issue of fsldma driver's VIRT_TO_BUS dependence in Kconfig.
- Previous by thread: Re: 2.6.24-rc2: Network commit causes SLUB performance regression with tbench
- Next by thread: Re: 2.6.24-rc2: Network commit causes SLUB performance regression with tbench
- Index(es):
 |